

QML Architecture for COVID‑19 Classification Based on Synthetic Data Generation Using CGAN


CT scan (Medical imaging)
Computed tomography (CT) is an imaging procedure that uses special x-ray equipment to create detailed pictures, or scans, of areas inside the body. It is sometimes called computerized tomography or computerized axial tomography (CAT).

Precision (P):
The fraction of true positives (TP, correct predictions) from the total amount of relevant results, i.e., the sum of TP and false positives (FP). For multi-class classification problems, P is averaged among the classes. The following is the formula for precision.
$$P=\frac{TP}{TP+FP}$$
Recall(R):
The fraction of TP from the total amount of TP and false negatives (FN). For multi-class classification problems, R gets averaged among all the classes. The following is the formula for recall.
$$R=\frac{TP}{TP+FN}$$
F1 score(F1):
The harmonic mean of precision and recall. For multi-class classification problems, F1 gets averaged among all the classes. The following is the formula for F1 score.
$$F1=2 \times \frac{Precision \times Recall}{Precision + Recall}$$
GAN
A generative adversarial network (GAN) is a type of deep learning network that can generate data with similar characteristics as the input training data.
A GAN consists of two networks that train together:
Generator — Given a vector of random values as input, this network generates data with the same structure as the training data.
Discriminator — Given batches of data containing observations from both the training data, and generated data from the generator, this network attempts to classify the observations as "real" or "generated".

CGAN
A conditional generative adversarial network (CGAN) is a type of GAN that also takes advantage of labels during the training process.
Generator — Given a label and random array as input, this network generates data with the same structure as the training data observations corresponding to the same label.
Discriminator — Given batches of labeled data containing observations from both the training data and generated data from the generator, this network attempts to classify the observations as "real" or "generated".
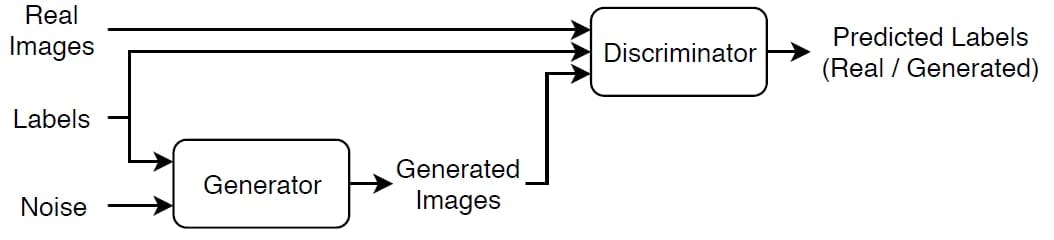
To train a conditional GAN, train both networks simultaneously to maximize the performance of both:
Train the generator to generate data that "fools" the discriminator.
Train the discriminator to distinguish between real and generated data.
To maximize the performance of the generator, maximize the loss of the discriminator when given generated labeled data. That is, the objective of the generator is to generate labeled data that the discriminator classifies as "real".
To maximize the performance of the discriminator, minimize the loss of the discriminator when given batches of both real and generated labeled data. That is, the objective of the discriminator is to not be "fooled" by the generator.
Ideally, these strategies result in a generator that generates convincingly realistic data that corresponds to the input labels and a discriminator that has learned strong feature representations that are characteristic of the training data for each label.
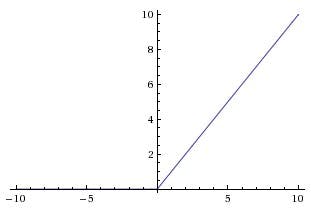
ReLu
The Rectified Linear Unit is the most commonly used activation function in deep learning models. The function returns 0 if it receives any negative input, but for any positive value x it returns that value back. So it can be written as
$$f(x) = max(0,x).$$
Activation functions serve two primary purposes:
Help a model account for interaction effects. What is an interactive effect? It is when one variable A affects a prediction differently depending on the value of B. For example, if my model wanted to know whether a certain body weight indicated an increased risk of diabetes, it would have to know an individual's height. Some bodyweights indicate elevated risks for short people, while indicating good health for tall people. So, the effect of body weight on diabetes risk depends on height, and we would say that weight and height have an interaction effect.
Help a model account for non-linear effects. This just means that if I graph a variable on the horizontal axis, and my predictions on the vertical axis, it isn't a straight line. Or said another way, the effect of increasing the predictor by one is different at different values of that predictor.